Une chaîne de caractères (string ou str en abrégé) est une suite de données de lettres ou de chiffres (ou les deux) encadrée par des guillemets ou des apostrophes. Nous utiliserons toujours, par souci de commodité et de cohérence, le préfixe u pour le codage Unicode et les guillemets pour pouvoir utiliser l’apostrophe dans la chaîne de caractères.
La fonction print() permet d’afficher la chaîne de caractère en question sans préciser si le codage est unicode ou non.
>>> test = u"J'aime python"
>>> test # Appel de la chaîne de caractères test avec son encodage
u"J'aime python"
>>> print(test) # Affichage de la chaîne de caractères test
J'aime python
La séquence \n dans une chaîne provoque un saut à la ligne alors que le \t provoque une tabulation. L’exemple suivant nous permet d’apprécier la différence entre l’affichage et l’appel d’une chaîne de caractère.
>>> test2 = u"J'aime \t python \n et la physique surtout"
>>> test2
u"J'aime \t python \n et la physique surtout"
>>> print(test2)
J'aime python
et la physique surtout
Note
Les triples guillemets servent à encadrer une chaîne de caractères avec des symboles réservés. On signale à Python que ce qui est entre 3 guillemets est une chaîne de caractères pure.
Les accents ne sont pas pris en compte sous la forme native de Python. Python ne sait pas comment convertir les caractères Unicode en ASCII, c’est pour cela qu’il utilise x82b, x88... On contourne la difficulté en précisant l’encodage lors de l’affichage (ici Latin-1 = ISO 8859-1).
>>> test3 = u"La chêvre hébétée bêla sur un agneau de façon éphémère, où se croyait-elle ?"
>>> test3
u'La ch\x88vre h\x82b\x82t\x82e b\x88la sur un agneau de fa\x87on \x82ph\x82m\x8are, o\x97 se croyait-elle ?'
>>> print(test3)
ERROR: An unexpected error occurred while tokenizing input
The following traceback may be corrupted or invalid
The error message is: ('EOF in multi-line statement', (15, 0)
>>> print test3.encode('latin-1') # Précision de l'encodage, ici latin 1
La chêvre hébétée bêla sur un agneau de façon éphémère, où se croyait-elle ?
Note
C’est l’intérêt du pseudo commentaire # -*- coding: utf-8 -*- dans le chapitre sur le fichier de base.
La fonction len() permet d’afficher la longueur de la chaîne de caractères, c’est à dire le nombre de caractère qu’elle contient (y compris les espaces!). Elle est nativement intégrée dans Python.
>>> len(u"Landau")
6
Il s’agit ici de récupérer certains caractères suivant leur ordre d’apparition dans la chaîne. On peut récupérer un caractère ou une partie de la chaîne en utilisant les crochets (symbole de l’indice des caractères).
>>> chaine = u"La physique c'est fantastique"
>>> chaine[0] # Attention, l'incrément commence à 0
u'L'
>>> chaine[10] # Attention, l'incrément commence à 0
u'e'
>>> chaine[12:29] # Récupérer une partie de la chaîne 12 à 29
u"c'est fantastique"
>>> chaine[:11] # les 11 premiers caractères
u'La physique'
>>> chaine[11:] # Tout sauf les 11 premiers caractères
u" c'est fantastique"
L’opération consiste à “coller” 2 chaînes de caractères pour en faire une nouvelle. La fonction "+" sert à effectuer cette opération.
>>> ch1 = u"Physique "
>>> ch2 = u"- Chimie"
>>> ch3 = ch1 + ch2 # Concaténation
>>> print(ch3)
Physique - Chimie
On ne peut concaténer que 2 chaînes de caractères ainsi si l’on veut concaténer un nombre, il faut d’abord le convertir en chaîne de caractères.
>>> from scipy import *
>>> ch1 = u"le nombre pi vaut : "
>>> ch2 = str(pi)
>>> ch3 = ch1 + ch2 # Concaténation
>>> print(ch3)
le nombre pi vaut : 3.14159265359
Un caractère particulier peut servir de marqueur pour séparer une chaîne de caractère en plusieurs parties en repérant le caractère choisi pour séparer la chaîne. La fonction split() sert à effectuer cette opération. Dans un premier exemple, la chaîne est séparée via le caractère “y”
>>> ch3 = u"Physique - Chimie"
>>> ch3.split("y")
[u'Ph', u'sique - Chimie']
Dans un second exemple, la chaîne est séparée via le caractère “i” (elle est donc séparée en 4)
>>> ch3 = u"Physique - Chimie"
>>> ch3.split("i")
[u'Phys', u'que - Ch', u'm', u'e']
Il est enfin possible de récupérer une chaîne en particulier. Dans cet exemple, la seconde :
>>> ch3 = u"Physique - Chimie"
>>> a = ch3.split("i")
>>> a[1] # Attention, l'incrément commence à 0
u'que - Ch'
De nombreuses fonctionnalités concernant les chaînes de caractères sont disponibles en python (décompte d’un caractère, index d’un caractère, présence ou non d’un caractère, mise en minuscules ou en majuscules...). Nous renvoyons le lecteur intéressé au site suivant suivant pour une lecture rapide et cet autre site pour une liste exhaustive.
Pour afficher du texte en latex, il suffit de rajouter le préfixe r devant le texte unicode. Par exemple, si l’on veut afficher \(\alpha\), la chaîne de caractères correspondante sera text_en_latex=ur"$\alpha$" Le préfixe u signale l’unicode, le r l’écriture latex et les $ le mode math.
# -*- coding: utf-8 -*-
"""
Création de texte en latex dans un graphique
"""
from __future__ import division
from scipy import *
from pylab import *
text(-8,0, ur"$e^{-j\times\pi}=-1$", fontsize=80, color='b') # Texte en position -10, 0
xlim(-10, 10) # Limites de l'axe des abscisses
ylim(-5, 5) # Limites de l'axe des ordonnées
show()
Ce qui donne
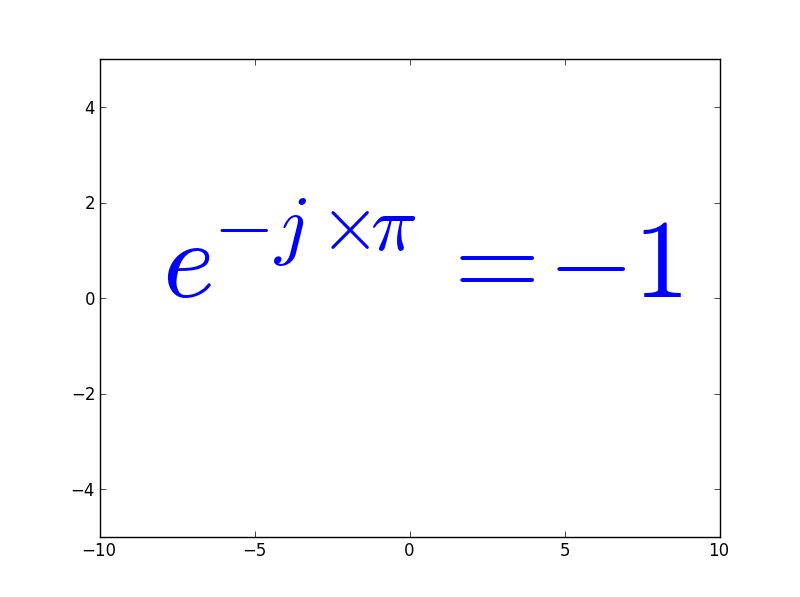
Quelques équations de la physique (Quelles sont elles ?)

Remarque
Le préfixe u qui signale l’unicode est nécessaire lorsque qu’on veut perndre en charge les accents en tex sans pour autant coder ceux-ci. Par exemple, ur"étoile" sera reconnu alors que r"étoile" signalera un message d’erreur. Il convient de taper r"\'etoile" si l’on veut coder l’accent sans l’unicode.
Voici quelques formules élémentaires en latex
Pour mettre en indice ou en exposant, il faut utiliser les symboles '_' and '^' avec, entre accolades, l’argument à placer en indice ou en exposant ; ainsi ur"$\alpha_{12} > \beta^{34}_{12}$" affichera
Les sommes et les intégrales placent automatiquement les bornes au dessus et en dessous du symbole. Ainsi, ur"$\Im\left(H\right)=\int_{0}^{\infty}\frac{dx}{\sqrt{1+\sqrt{\epsilon_{0}x}}}$" affiche
Enfin, les fractions et les racines, elles aussi, prennent leurs arguments entre accolades : ur"$\frac{1}{x}$" affiche \(\frac{1}{x}\) et ur"$\sqrt{2}$" affiche \(\sqrt{2}\)
Quelques décorations dont les accents
Commandes Résultats Commandes Résultats Commandes Résultats \acute a \'a \(\acute a\) \dot a or \.a \(\dot a\) \vec a \(\vec a\) \bar a \(\bar a\) \grave a or \`a \(\grave a\) \overline{abc} \(\overline{abc}\) \breve a \(\breve a\) \hat a or \^a \(\hat a\) \widehat{xyz} \(\widehat{xyz}\) \ddot a \"a \(\ddot a\) \tilde a or \~a \(\tilde a\) \widetilde{xyz} \(\widetilde{xyz}\)
Les lettres grecques minuscules et majuscules
Commandes Résultats Commandes Résultats Commandes Résultats Commandes Résultats \alpha \(\alpha\) \omega \(\omega\) \varrho \(\varrho\) \Delta \(\Delta\) \beta \(\beta\) \phi \(\phi\) \varsigma \(\varsigma\) \Gamma \(\Gamma\) \chi \(\chi\) \pi \(\pi\) \vartheta \(\vartheta\) \Lambda \(\Lambda\) \delta \(\delta\) \psi \(\psi\) \xi \(\xi\) \Omega \(\Omega\) \digamma \(\digamma\) \rho \(\rho\) \zeta \(\zeta\) \Phi \(\Phi\) \epsilon \(\epsilon\) \sigma \(\sigma\) \Pi \(\Pi\) \eta \(\eta\) \tau \(\tau\) \Psi` \(\Psi\) \gamma \(\gamma\) \theta \(\theta\) \Sigma \(\Sigma\) \iota \(\iota\) \upsilon \(\upsilon\) \Theta` \(\Theta\) \kappa \(\kappa\) \varepsilon \(\varepsilon\) \Upsilon \(\Upsilon\) \lambda \(\lambda\) \varkappa \(\varkappa\) \Xi \(\Xi\) \mu \(\mu\) \varphi \(\varphi\) \mho \(\mho\) \nu \(\nu\) \varpi \(\varpi\) \nabla \(\nabla\)
Pour les symboles plus exotiques, on pourra se reporter à la documentation de Matplotlib p.42-56.
